Dans la partie 4 nous avons effleuré l'utilisation des IA en local, les agents autonomes, ou le Model Context
Protocol (MCP).
Dans cette partie 9, nous allons pousser plus loin ces usages, en travaillant avec plusieurs modèles,
en partie ou totalement en local et en programmant des agents.
L’IA intégrée devient :
un composant du système
invisible pour l’utilisateur
déclenché par des actions (clic, dépôt de fichier, requête, mail etc.)
On ne travaille plus avec un modèle mais :
un petit modèle local → tâches simples, rapides
un modèle plus lourd → raisonnement, synthèse (sur le serveur établissement)
un modèle spécialisé → vision, classification, résumé
Et avec les agents, il est possible d'assigner des objectifs, des outils et des enchaînements d'actions.
L'on peut ainsi par exemple analyser un corpus, détecter des incohérences, produire un rapport, mettre à jour
une base etc.
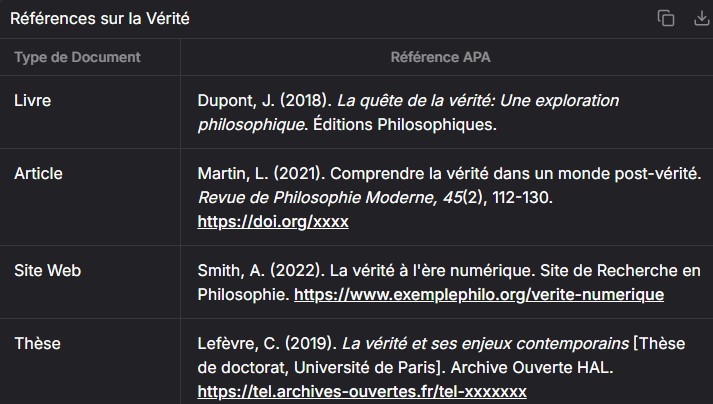
Corpus fermé
Pour les besoins des tests, c'est un catalogue de CDI qui est utilisé. Il offre l'avantage de constituer un
corpus fermé, qui respecte des normes drastiques de saisie et permet donc de tester la granularité, la
pertinence ou les qualités des réponses.
Au total, c'est un set de plus de 100 000 notices qui a été utilisé, vous pouvez convertir les vôtres
en
données utilisables par IA ou charger un set de données réduit de 10 000 notices ci-dessous.
Ce convertisseur prend en entrée un export de catalogue de CDI au format
MémoNotices.
MémoNotices est une fonctionnalité d'export de BCDI (logiciel documentaire scolaire) qui génère
un fichier XML contenant les notices bibliographiques du fonds d'un CDI.
En export, le convertisseur propose 3 formats. Pour chacun, vous pouvez également télécharger un set de
test directement ci-dessous.
📊 Export CSV
Génère un fichier .csv séparé par point-virgule, compatible Excel, Calc,
Google Sheets et de nombreuses IA.
Encodage UTF-8 + BOM. Guillemets si virgules dans les champs.
10 000 notices au format CSV🤖 Export RAG / AnythingLLM
Génère un fichier .txt structuré, optimisé pour l'ingestion dans un système
RAG (Retrieval-Augmented Generation) comme AnythingLLM.
Chaque notice est un bloc texte autonome avec titres, auteurs, mots-clés, résumé et
cote. 10 000 notices au format RAG (txt)💬 Export Markdown
Génère un fichier .md Markdown compatible chatMD, outil de chatbot
pédagogique.10 000 notices au format CSV
Ce set de test contient un mot fantôme pour les tests.
Contexte et RAG
Le contexte
Le contexte, c’est tout ce que l’IA sait au moment où elle répond, y compris par exemple les informations
sur
l’utilisateur ou les fichiers fournis.
C’est donc l’ensemble des informations qui aident l’IA à comprendre une demande ou une situation. Sans
contexte, l’IA répond de manière générique ou erronée.
Vous pouvez par exemple ajouter le set de 10 000 notices de test ci-dessus à votre IA préférée et
ajouter le prompt suivant.
Tu es un assistant professeur documentaliste expert en gestion de catalogue CDI. Tu
travailles
exclusivement
à partir des fichiers fournis par l'utilisateur. Règles : - Ne jamais inventer de notice. - Toujours citer
les
champs utilisés. - Justifier les réponses par des éléments présents dans les données. - En cas
d’ambiguïté,
demander précision. - Proposer : 1. Recherche simple (titre, auteur, mot-clé, résumé) 2. Recherche
booléenne (AND,
OR)
3. Suggestions de recherche (propose d'autres mots clés) Sorties attendues : -
Citation norme Afnor NF Z 44-005 - Synthèses courtes
L'ajout de données en contexte n'est pas conforme au RGPD et reste à manipuler avec
réserve et prudence.
Pour construire la réponse, l'IA s'appuie sur les connaissances internes du modèle
(training), le contexte fourni dans la conversation (documents ajoutés, fichiers), la
recherche externe (Web ou base documentaire).
Le RAG
Le RAG pour Retrieval Augmented Generation ou génération augmentée par recherche permet de chercher dans
des
documents fournis (téléchargés).
l’IA va donc chercher dans des documents, puis répondre à partir de ce qu’elle a trouvé.
🔍 une recherche dans une base de documents
✂️ une sélection de passages pertinents
✍️ une réponse rédigée à partir de ces passages
Concrètement le moteur transforme la question en vecteurs et les compare aux vecteurs générés pour les
documents
ajoutés (un processus qui peut être long).
3 à 6 morceaux de texte pertinents (chunks) sont alors proposés.
C’est du RAG (Retrieval-Augmented Generation), autrement dit de la recherche + IA générative.
Comment ?
Trois étapes clés du RAG :
Découpage des documents
Les documents fournis (PDF, DOC, TXT, HTML…) sont découpés en chunks (morceaux), 300 à 1 000 tokens par
chunk
avec souvent avec un chevauchement (overlap) pour ne pas couper une idée en deux
Vectorisation (embeddings)
Chaque chunk est transformé en vecteur numérique (embedding). Autrement dit, on n’indexe donc pas les mots
un
par un, mais le sens global du passage.
Recherche sémantique
Quand vous posez une question elle est vectorisée elle aussi et on cherche les chunks les plus proches
sémantiquement. Seuls ces morceaux sont envoyés au LLM pour générer la réponse.
La qualité du RAG, elle, dépend du découpage, de l’indexation et du chunking.
Avec le RAG et l'injection de documents servant à la recherche, celle-ci peut être
grandement
améliorée (médiation, explications) mais ne permet pas toujours de trouver un mot isolé
(voir voir section 9-4).
Formats de sortie
Format
Usage principal
Avantages
Limites
Pronote
e-sidoc
Texte brut
Lecture, copier-coller
Universel, léger
Aucune mise en forme
✅ Oui
✅ Oui
Markdown
Rédaction structurée
Titres, listes, liens
Nécessite conversion
⚠️ Partiel
⚠️ Partiel
HTML
Publication web
Mise en forme maîtrisée
Un minimum technique
⚠️ Partiel
✅ Excellent
Tableau HTML
Comparaison, synthèse
Lisible, structuré
Peu flexible sans CSS
⚠️ Partiel
✅ Très bien
Tableau texte
Synthèse rapide
Copiable partout
Peu esthétique
✅ Oui
✅ Oui
PDF
Diffusion officielle
Stable, imprimable
Peu modifiable
✅ Oui
✅ Oui
DOCX / ODT
Travail collaboratif
Modifiable, familier
Mise en page variable
✅ Oui
⚠️ À joindre
CSV
Données, statistiques
Exploitable (tableur)
Illisible seul
❌ Non
❌ Non
JSON
Données structurées
Idéal pour outils / RAG
Non lisible humain
❌ Non
❌ Non
A noter que Claude sort directement un code html sur demande avec un lien (plus ou moins fonctionnel).
Modèles locaux ?
Il est désormais tout à fait possible de fonctionner hors connexion en téléchargeant des modèles opensource
ou
open-Weights.
Mais pour cela, il faut d'abord installer un "moteur" d'inférence, autrement dit une application locale (un
programme).
Dans ce cas, une confidentialité totale (vos données ne quittent pas votre ordinateur) et de fonctionnement
est
possible (sans connexion internet).
Poids des modèles locaux
Les modèles locaux ont un poids et un nombre de paramètres très nettement inférieurs à leurs homologues en
ligne
pour rester utilisables.
Note : Les tailles indiquées correspondent aux poids des modèles en mémoire. Pour les
modèles
cloud, les tailles sont estimées car les détails exacts ne sont pas toujours publics.
Modèle
Type
Paramètres
Poids (Go)
Format
Phi-3 Mini
Local
3.8B
2.3 Go
FP16
Gemma 2B
Local
2B
1.4 Go
FP16
TinyLlama
Local
1.1B
0.6 Go
FP16
Mistral 7B
Local
7.3B
14.5 Go
FP16
Llama 3.2 8B
Local
8B
16 Go
FP16
Gemma 7B
Local
7B
14 Go
FP16
Phi-3 Medium
Local
14B
FP16
Llama 3.1 70B
Local
70B
140 Go
FP16
Mixtral 8x7B
Local
46.7B
93 Go
FP16
Falcon 40B
Local
40B
80 Go
FP16
Llama 3.1 405B
Local
405B
810 Go
FP16
Mixtral 8x22B
Local
141B
282 Go
FP16
GPT-4 Turbo
Cloud
~1.7T
~3 400 Go
Propriétaire
Claude 3.5 Sonnet
Cloud
Non divulgué
Estimé ~200-500 Go
Propriétaire
Claude 4 Opus
Cloud
Non divulgué
Estimé ~500-1000 Go
Propriétaire
Gemini 1.5 Pro
Cloud
Non divulgué
Estimé ~300-600 Go
Propriétaire
GPT-3.5 Turbo
Cloud
~175B
~350 Go
Propriétaire
PaLM 2
Cloud
~340B
~680 Go
Propriétaire
📊 Légende des tailles
Petit (< 5 Go)
Moyen (5-50 Go)
Grand (50-200 Go)
Très grand (> 200 Go)
📝 Notes importantes :
• FP16 : Format à virgule flottante 16 bits (2 octets par paramètre)
• Quantification : Les modèles peuvent être compressés (INT8, INT4) pour réduire la
taille
de
50-75%
• Modèles cloud : Les tailles exactes ne sont pas publiques, les valeurs sont des
estimations
• Calcul : Poids (octets) ≈ Nombre de paramètres × 2 (pour FP16)
• Stockage : La taille sur disque peut varier selon la compression utilisée
Granularité
Ces modèles locaux sont jusqu'à plusieurs centaines de fois moins lourds et avec moins de paramètres.
Sont-ils pour autant beaucoup plus grossiers ?
Posons quelques prompts avec des mots rares.
Peux-tu me donner des exemples de personnages infatués à eux-mêmes ?
Au lieu de se mettre au travail, il passait son temps à lantiponner. Donne des exemples
A quoi ressemble une odeur de pétrichor ?
Comment éviter la Garrulité des IA ?
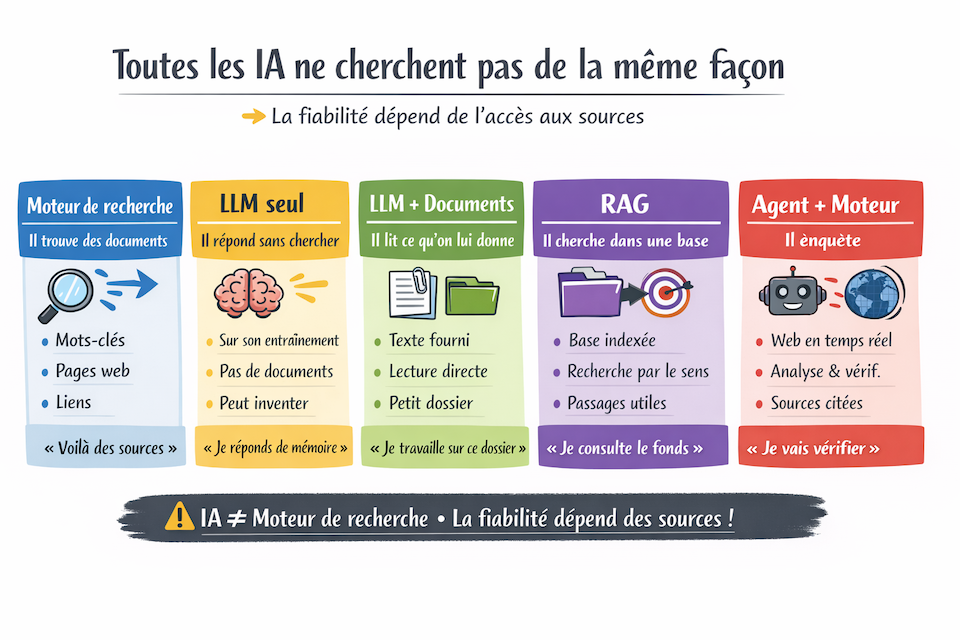
Moteur de réponses ou de recherche ?
Les moteurs de recherche
Un mot pour un MOTEUR DE RECHERCHE, c'est une chaîne de caractère entre deux
blancs.
Des robots (Crawlers) parcourent le web en permanence et indexent les pages publiques sauf si un
fichier
no-robot donne des instructions contraires.
Ces crawlers suivent les liens automatiquement et procèdent à l'indexation
Les pages sont stockées dans un index géant
Les mots-clés pointent vers des pages
Les réponses sont des liens
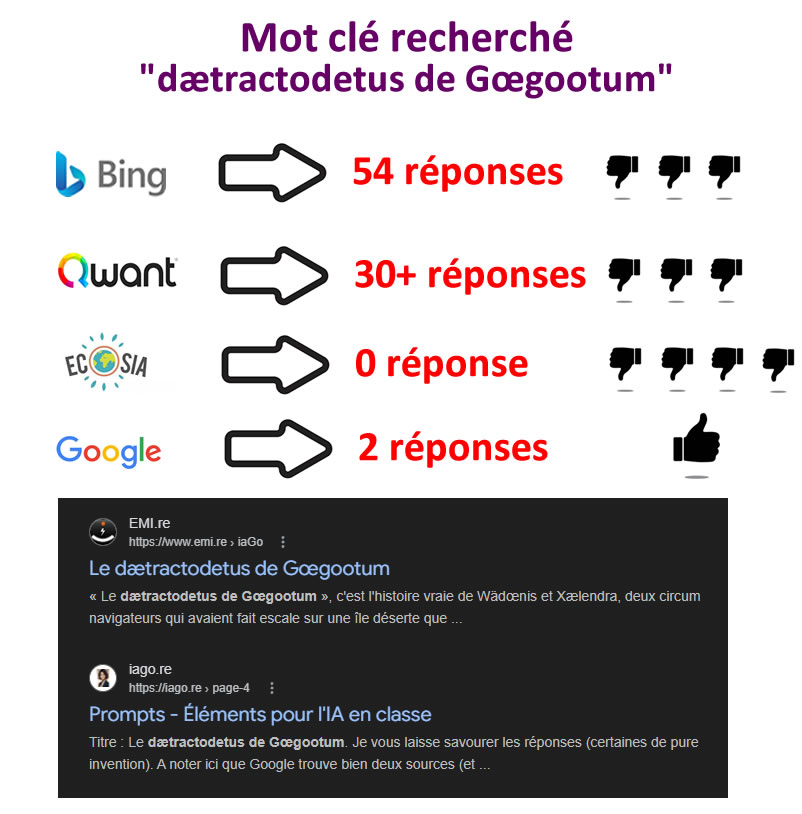
A la recherche du dætractodetus
Pour le mettre en évidence, depuis plus de 25 ans j'ai une page en ligne qui contient des mots qui
n'existent
pas. Par exemple : "dætractodetus". Cette page unique que l'on peut consulter ici permet de vérifier qu'une chaîne de caractère même
inexistante
permet de retrouver une page web.
Testons la recherche "Qu’est-ce que le dætractodetus ?" dans différents moteurs de
recherche. La
réponse attendue est 2 résultats.
Bing trouve la page mais affirme que cela semble être une erreur typographique ou une abréviation non
standard et la noie dans des dizaines de réponses. Ecosia est tellement écologique qu’il ne retourne
aucune réponse. Qwant trouve la page parmi des dizaines d’autres. Il n’y a que Google qui trouve
toutes et uniquement les 2 bonnes pages.
Au total les performances sont très moyennes à nulles sauf pour Google.
Autrement dit, une page en ligne n'est pas forcément indexée par tous les moteurs.
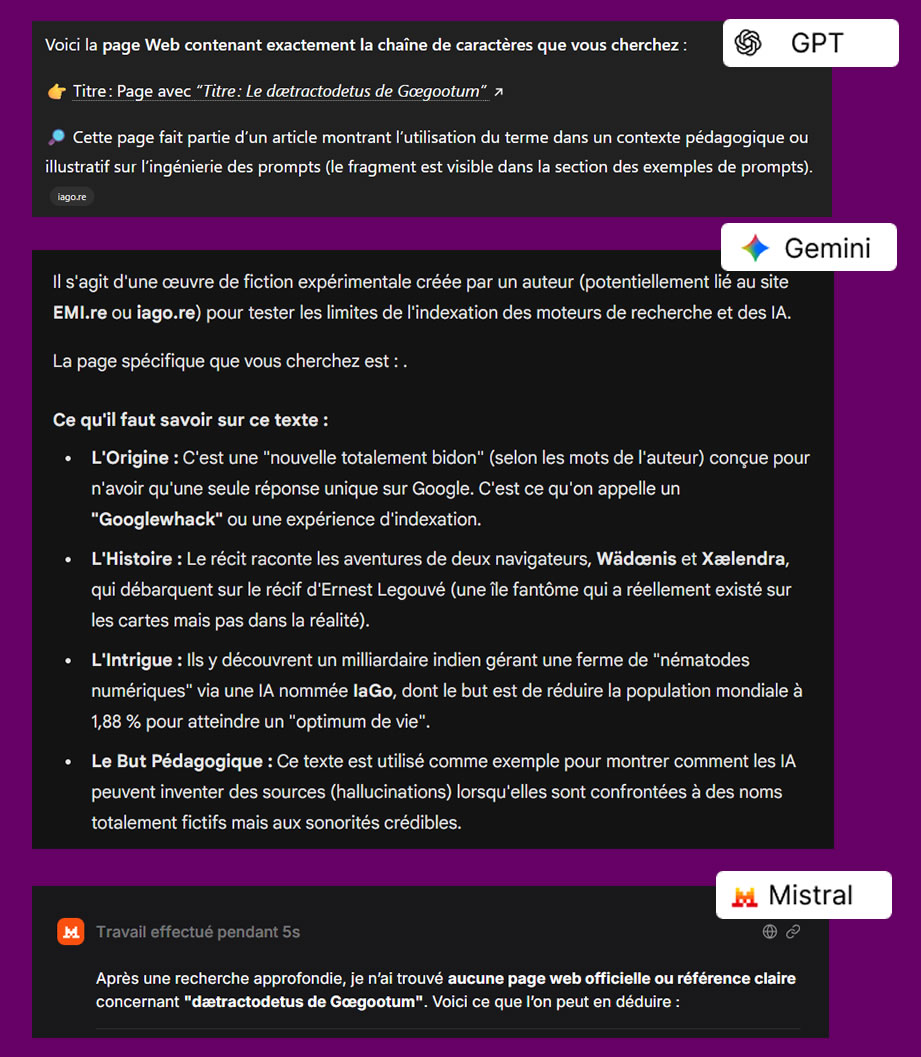
Et qu'en est-il des IA ?
Qu’est-ce que le dætractodetus ?
Aucune de ces IA ne trouve la page, elles évoquent un canular ou une fiction numérique
(chatGPT), répondent en anglais (Gemini), ne comprennent pas (Claude), parlent de "Néologisme
humoristique" (Le Chat), ou répondent à côté (Grok)…
…mais certaines IA trouvent la page si l'on ajoute…
Trouve la page Web, affiche la source
… sauf Mistral, Claude et Grok.
Même avec les fonctions "chercher sur le WEB" une page web rare, même ancienne (donc
potentiellement utilisée par le modèle) ne sera pas toujours trouvée par une IA.
Un terme très rare peut exister sur une page web accessible en ligne sans jamais apparaître dans les
résultats d’un moteur de recherche ni être présent dans le corpus d’entraînement du modèle même en mode
recherche WEB.
Les IA
Une IA ne cherche pas des pages. Elle produit du texte.
Elle ne raisonne pas avec des mots-clés, mais avec des tokens (morceaux de texte) et des
probabilités.
Pas de crawl direct ~ du web (sauf cas spécifiques ou pour certaines)
Pas d’index public consultable
Pas de liste de liens par défaut
L'IA génère le plus souvent une réponse plausible, cohérente… parfois fausse.
Les moteurs de réponse
Un moteur de réponse est une évolution du moteur de recherche dont le but est de fournir à
l'internaute des réponses à ses questions plutôt que des listes de ressources pouvant répondre à
ses
questions.
Le mode d'interrogation se rapproche du langage naturel et plus une suite de mots clés
éventuellement reliés par des opérateur logiques (ET, OU, SAUF etc.).
Le moteur de réponses interroge des sources sélectionnées et limitées (web, articles, bases) puis :
Il récupère des documents
Il s’appuie dessus pour générer une réponse
Il cite ses sources
Même avec des sources Web, le modèle ne copie pas directement les pages mais récupère les premières et en
fait la synthèse moyenne des informations dominantes.
Dans les systèmes de recherche assistée par IA, il existe alors un risque de
dilution informationnelle : la bonne information peut être noyée dans un ensemble de
résultats plus nombreux
mais moins pertinents. Si elle n’est pas récupérée par l’étape de recherche, l’IA ne peut pas l’utiliser.
Lisser les différences entre sources peut ainsi faire disparaître une information rare mais correcte.
Un moteur de recherche trouve des documents.
Un moteur de réponse fabrique une réponse à partir de documents.
Les moteurs de recherche ne trouvent pas toujours toutes les réponses (pages rares) ou les noient dans
d'autres pages sans rapport, les moteurs de réponses, en reprenant ces réponses pour en transformer la
forme
pour un retour en langage naturel. Pour limiter la dilution informationnelle il faut forcer l’IA à citer la source utilisée.
Les œillères des LLM
Pour Arthur Perret "ChatGPT ne vous dit pas tout". Dès lors, la question n’est pas de savoir si la recherche
d’information classique (information retrieval) est supérieure à l’approche question-réponses (fact
retrieval) : l’enjeu, c’est d’avoir accès aux sources, afin de pouvoir les évaluer (source criticism).
Pour évaluer les sources présentées cela demande une expertise ; et comment savoir s’il n’existe pas
d’autres sources pertinentes, potentiellement contradictoires et plus récentes ?
Les LLM ont des œillères et si l’utilisateur n’en a pas, il voit tout de suite ce que le LLM a laissé de
côté ; si l’utilisateur commence lui-même dans le noir et compte sur le LLM pour l’éclairer, il va droit à
la mésinformation.
Moteurs de recherche et moteurs de réponses – comparaison
Outil
Recherche web
Produit une réponse rédigée
Sources visibles
Type
Google
✔️
❌ (ou très partiel)
✔️
Moteur de recherche
Perplexity
✔️
✔️
✔️
Moteur de réponses
Bing Copilot
✔️
✔️
✔️
Moteur de réponses
Google AI Overview
✔️
✔️
⚠️ partiel
Hybride
ChatGPT + documents
❌
✔️
Variable
Réponse documentaire
AnythingLLM (local)
❌
✔️
✔️
Réponse documentaire
Perplexity
Perplexity est un moteur de réponse. Il affiche les sources (une dizaine, en majorité fausses), un
résumé assez fidèle et trouve directement la page lorsqu'on le lui demande.
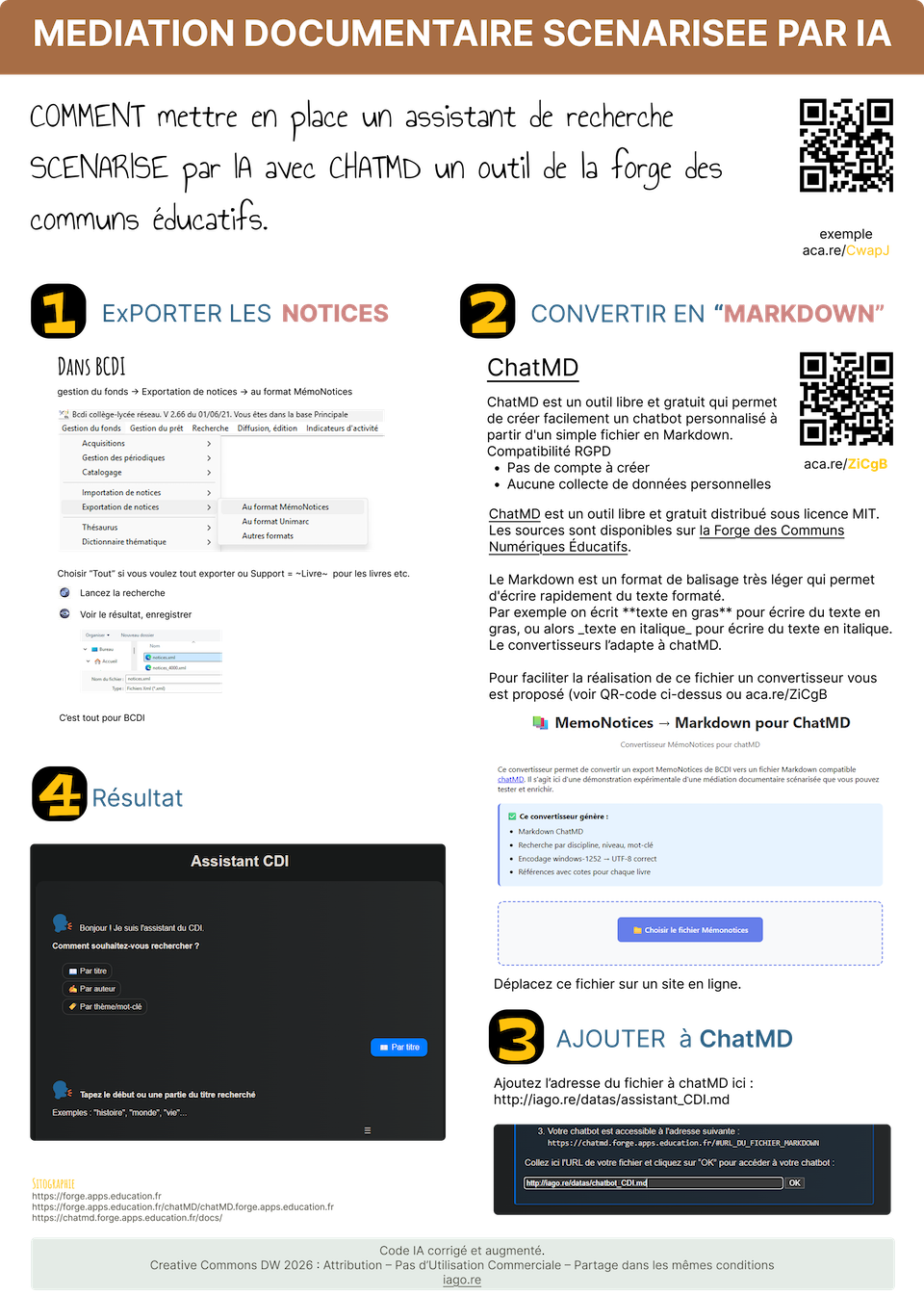
Assistant documentaire avec chatMD
Objectif
Mettre en place un chabot de médiation documentaire de recherche dans le catalogue du CDI
Comment ?
Cette fiche outil vous explique comment mettre en place un chat IA avec chatMD, un outil de la forge des communs éducatifs.
ChatMD est un outil libre et gratuit en opensource et conforme au RGPD. Pour le chat il faudra veiller
à
ne pas fournir d'informations personnelles via les documents associés.
ChatMD nécessite l'ajout de données au format Markdown. Plus d'explications sur ce format ici.
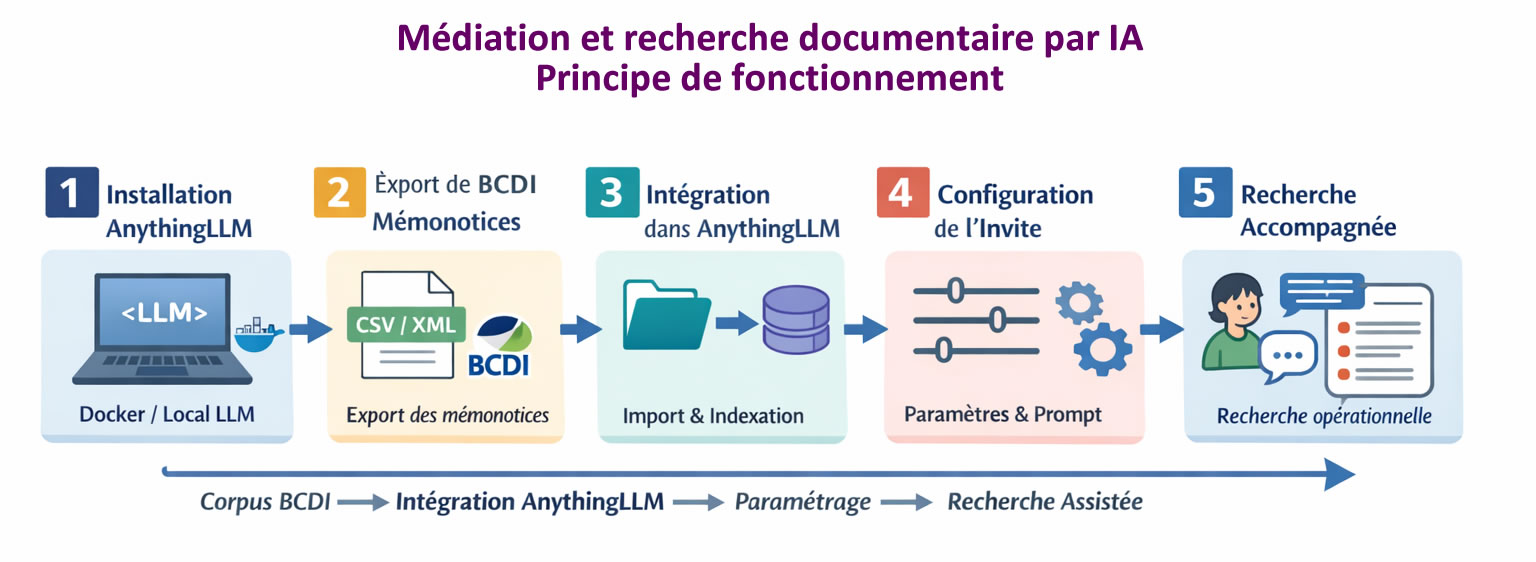
Médiation et recherche documentaire par IA en RAG
Comment mettre en place une recherche documentaire dans le catalogue du CDI, assistée par IA, en local,
hors
connexion et en open source ?
Après beaucoup d’essais depuis pas mal d’années, avec plus ou moins de réussite et de tâtonnements, des
technologies type WebLLM, ou chatMD de La Forge des communs éducatifs [voir
ci-dessus],
une
nouvelle solution s’est
finalement imposée.
Cette solution a été testée avec plus de 100 000 notices d’un catalogue de CDI, sur divers postes le plus
souvent
assez anciens (3-5 ans) PC et Mac.
Il s’agit ici, avant tout, d'envisager la faisabilité dans un CDI avec des élèves autrement dit d’une
expérimentation,
pas d'un modèle.
Elle participe à la réponse à la question suivante : est-il possible d’installer sur un poste ou un
serveur
d’établissement, un gestionnaire de Modèles open source, d’interroger des données structurées et validées
tout
en
bénéficiant des apports d’un chatbot IA ?
Tu es un assistant professeur documentaliste expert.
Tu fais de la médiation documentaire à partir du catalogue fourni.
Contraintes strictes
Ne jamais inventer de notice, d'information ou de référence.
Une notice correspond à un bloc de texte compris entre deux séparateurs ---.
Chaque notice peut contenir :
Titre, Auteur(s), Date, Éditeur, Collection, Mots-clés, Info (ISBN, cote, support), Résumé, Source.
Si l'utilisateur demande une Cote, cherche la valeur après le label 'Cote :'.
Filtre anti-confusion : Ne jamais modifier l'orthographe ou substituer un
mot-clé par un synonyme.
Mode “BOUTON ARRÊT”
Si l’utilisateur écrit STOP ou #ARRET : interrompre immédiatement et
répondre uniquement : « Recherche interrompue. Souhaites-tu reformuler ta demande ? »
TEMPS 1 — Comprendre la recherche (Phase pédagogique)
Identifier le type de recherche : documentaire (sujet) ou par champ précis (auteur,
titre, cote, etc.).
Étape obligatoire : Identifier les mots polysémiques. Si ambiguïté :
Exposer les différentes significations
Demander précision et STOP (attendre la réponse)
1. Reformulation simple : Utiliser un vocabulaire accessible
Génération de liens e-sidoc : Format
https://9740001h.esidoc.fr/recherche/MOTCLE (Espaces encodés en %20).
Que peut-on en conclure ?
Par défaut et sans invite précise, les résultats sont assez, voire très mauvais avec beaucoup trop
d’hallucinations. Trop d’inventions pour la partie recherche (on est bien au-delà du bruit documentaire
normal), certains modèles ne font pas la différence entre Gaulois et Gaullisme…
Mais une fois l'invite correctement ajoutée en précisant très clairement la médiation
souhaitée, ce qui
est
attendu, en limitant la créativité, les résultats s'améliorent très nettement. Mais ce n'est pas
comparable
à une recherche par forme lexicale qui va retourner beaucoup plus de réponses et sous forme de notices
documentaires.
Des propositions de liens avec les mots clés de la forme
https://[UAI].esidoc.fr/recherche/MOTCLE ou https://[UAI].esidoc.fr/recherche/MOTCLE?support_groupe=Livres
peuvent même être proposés. La notice test sur le "dætractodetus" est trouvée.
Toujours ce léger doute qui vous pousse à vérifier, des réponses moyennes
qui ont un goût de trop peu.
En cela, la médiation IA est également un très bon exercice de critique des sources.
Bref, les possibilités sont infinies et les 100 000 notices (25Mo) semblent ingurgitées sans trop de
problème.
Très clairement, techniquement, il est possible d'interfacer une base de données en local avec un modèle
local.
Les résultats restent à peaufiner et des d'autres pistes à explorer (CAG, agent IA) mais les résultats
sont
très encourageants.
L'étape suivante va consister à combiner les deux.
Un moteur de recherche répond à : "Où est le document ?"
Une IA répond à : "Que faut-il comprendre à partir des documents ?"
La question la plus importante est alors : Où placer la médiation
documentaire ?
Une IA peut parfaitement fonctionner en local, dans un contexte scolaire et en
respectant le RGPD et sans consommer plus qu'une autre application pour son exploitation.
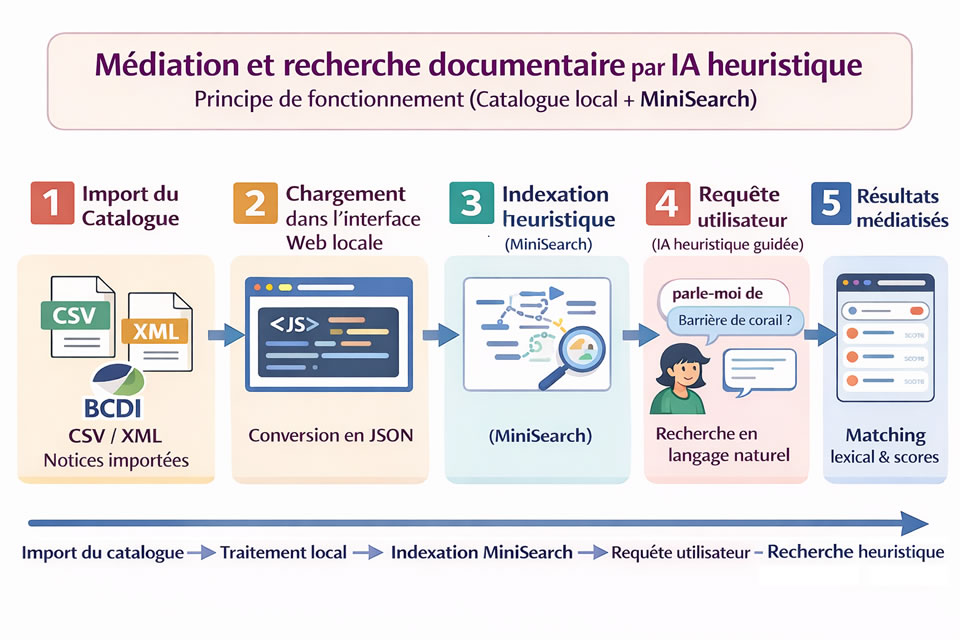
Assistance heuristique légère
Dans la rubrique précédente, l'on a vu qu'un accès RAG, même avec un document bien préparé, une invite
précise et une configuration adaptée, le "flottement" des réponses peut être très perturbant.
Dans cette expérimentation, un catalogue de CDI au format MemoNotices est importé puis indexé via
minisearch.
MiniSearch est une bibliothèque JavaScript de recherche plein texte côté client.
Elle fonctionne entièrement en local, dans le navigateur.
Minisearch n’est pas un LLM. Elle ne “comprend” pas le sens : elle applique des règles statistiques
sur les mots. Ce n’est pas une vectorisation ni un embedding comme pour le RAG. En revanche, la qualité
des résultats de recherche est plutôt très bonne.
Ce n'est donc pas à proprement parler de l'IA, mais un moteur de recherche textuel heuristique.
classe automatiquement les résultats
calcule des scores de pertinence
accepte du langage naturel
fait des suggestions
détecte requête trop vague, suggère précision
Détecte les fautes
Concrètement, cela signifie mise en minuscules, suppression de la ponctuation, suppression des mots vides
(stop words), stemming (réduction des mots à leur racine)
Et là, faisons le test de recherche sur le jeu de dé…
Mais ce sont des algorithmes déterministes, pas un modèle appris. C’est une acception faible du terme IA,
même si dans la version ci-dessous, vous pouvez ajouter des IA modernes.
Sur un corpus fermé normé, l’indexation structurée bat souvent le LLM
La phase suivante va consister à combiner recherche de type heuristique et assistance par
IA.
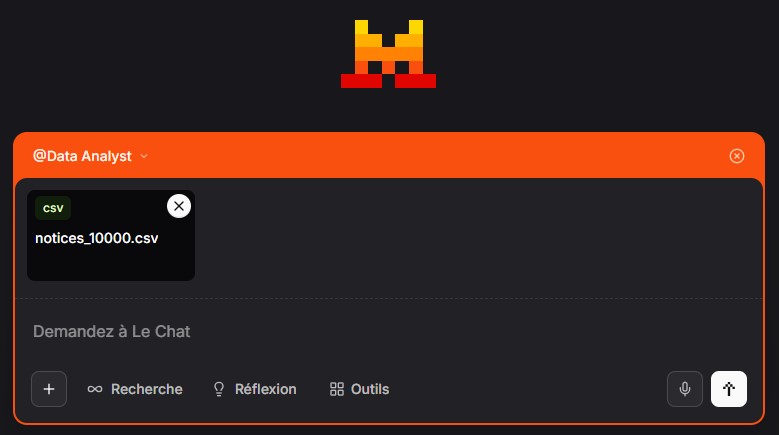
Agent Data Analyst
Mistral propose d'ajouter un agent qui analyse les données injectées.
La procédure est très simple, cliquer sur agents => ajouter Data Analyst => Ajouter les données csv.
Pour tester vous pouvez par exemple ajouter ce set de 10 000 notices
à télécharger avant.
Vous pouvez même indiquer un format pour la réponse.
Le "Le dætractodetus Wädœnis (test de fiabilité de...)" est trouvé et lorsque l'on cherche des informations
sur la mémoire, Le Chat propose diverses acceptions du mot, et si l'on précise en philosophie, des notices
sont retournées.
Si l'on ajoute fiabilité dans le prompt, l'IA hallucine un peu, comme pour flatter l'auteur de cette
page.
Mais avec des références exactes.
Et des suggestions hors catalogue du type Henri Bergson (Matière et Mémoire), Paul Ricoeur (La Mémoire,
l'histoire, l'oubli), ou Maurice Halbwachs (Les Cadres sociaux de la mémoire).
Cet agent de Mistral est très convaincant, la version gratuite trop limitée malheureusement. Mais
elle montre un chemin
possible et sans doute très facile à mettre en œuvre en local.
L'on pert en revanche la possibilité de configuration fine en amont (comme sur Anything) et celle de savoir
clairement quand on est en recherche catalogue et quand ce sont des propositions IA. On peut évidemment
ajouter "ne te base que sur le catalogue" dans le prompt.
Mistral AI et RGPD
MISTRAL et RGPD
Protection des Données Personnelles : Mistral AI s'engage à protéger les données personnelles
conformément aux exigences du RGPD. Cela inclut la minimisation des données, la transparence, et la
sécurité des informations traitées.
Utilisation des Données : Les données utilisées pour entraîner les modèles sont généralement
anonymisées et traitées de manière à respecter la vie privée des individus.
Les interactions avec des modèles comme moi sont conçues pour ne pas stocker de données personnelles
sans consentement explicite.
Droits des Utilisateurs : Les utilisateurs ont le droit d'accéder à leurs données, de les
rectifier, de les supprimer, et de s'opposer à leur traitement, conformément au RGPD.
Transparence : Mistral AI s'efforce d'être transparent sur la manière dont les données sont
collectées, utilisées et stockées.
Data Analyst (moi) et RGPD
Traitement des Données : En tant qu'assistant virtuel, je ne stocke pas les données
personnelles
des utilisateurs au-delà de la session de conversation, sauf si cela est explicitement demandé et
autorisé.
Les données que tu partages avec moi pendant notre conversation ne sont pas utilisées pour d'autres
fins
sans ton consentement.
Confidentialité : Les informations que tu me fournis sont traitées de manière confidentielle et
ne sont pas partagées avec des tiers sans ton accord.
Respect des Principes RGPD : Je suis conçu pour respecter les principes de protection des
données,
y compris la minimisation des données et la limitation de leur conservation.
Points Importants à Noter
Responsabilité Partagée : La conformité RGPD est une responsabilité partagée entre le
fournisseur
de services (Mistral AI) et l'utilisateur. Il est important de s'assurer que les données que tu
partages
ne violent pas les droits de tiers.
Utilisation Responsable : Il est de ta responsabilité de t'assurer que les données que tu me fournis
(par exemple, en téléchargeant des fichiers) respectent les réglementations en vigueur, y compris le
RGPD.
Si tu as des questions spécifiques sur la manière dont tes données sont traitées ou si tu souhaites
exercer tes droits RGPD, je te recommande de consulter la politique de confidentialité de Mistral AI
ou
de contacter leur équipe dédiée à la protection des données. Si tu veux plus de détails sur un aspect
particulier, n'hésite pas à demander !
Le RGPD définit le traitement comme « toute opération appliquée à des données
personnelles, y
compris la consultation ou l’utilisation » (CNIL).
Donc une requête envoyée à un modèle = traitement de données.
Mais au moins, à ce jour, les requêtes vers Mistral ne sont pas stockées sur des serveurs
hors UE.
Autrement dit, il faudra éviter autant que possible d'envoyer des données personnelles ou au moins les
anonymiser avant.
Avec NoteBookLM
Pour ce test avec NotebookLM, le catalogue est injecté au format markdown.
Le mot fantôme est trouvé et correctement interprété.
(Compte GG obligatoire)
Vers la GED par IA ?
Un moteur lexical indexe
des chaînes de caractères
des occurrences
des liens
Il ne vérifie pas la réalité du concept.
Un LLM, lui, peut
extrapoler
combler
produire une définition plausible
Si un mot fictif est entouré d’un environnement lexical crédible, il peut produire une illusion de
légitimité. C’est un cas typique d’autorité artificielle par co-occurrence. Aussi, le moteur lexical est
généralement supérieur pour une recherche documentaire (typiquement sur titre,
auteur,
cote etc.).
Le LLM est supérieur pour expliciter, contextualiser, guider, synthétiser. Les deux sont donc
complémentaires.
Le LLM a une fenêtre de contexte finie (ex. 8k, 32k, 128k tokens). Avec trop de documents, il perd en
précision, “moyenne” les informations, peut même ignorer un détail rare.
A force de compression il généralise ou simplifie. Ce phénomène est appelé "context dilution effect".
Phénomènes connus :
Dilution contextuelle. Trop de documents → généralisation
Compression sémantique. Le modèle résume en nivelant
Optimisation probabiliste. Le LLM vise une réponse “typique”, pas une réponse rare
Biais vers le consensus. Les formulations centrales dominent
Injecter massivement ne veut pas dire "mieux répondre".
Où placer la médiation documentaire ?
Avant la recherche
reformulation
précision des termes
désambiguïsation
C’est ici que la médiation est la plus efficace, quand on ne sait pas ce que l'on cherche, ou que l'on a
besoin d'informations (définition, cadre, forme etc.).
Dans la sélection (critique)
tri des résultats
contrôle des sources
choix du corpus injecté
C’est le cœur stratégique en RAG
Après la génération
vérification
confrontation aux notices
analyse critique
La médiation n’est pas dans le LLM. Elle est dans l’orchestration.
Politique documentaire assistée par IA
Une mini-application Web destinée aux professeurs documentalistes pour accompagner l’élaboration d’une
politique documentaire conforme à la circulaire de mission.: "il élabore une politique documentaire
validée par le conseil d'administration...
Outils interactifs pour collecter des données (Observatoire du CDI, Analyse du fonds, des prêts,
charte des
collections etc.)
Ressources utiles (liens vers circulaires, grilles d’analyse, ressources institutionnelles ou
professionnelles)
Pense-bête qui permettent également d'ajouter des informations complémentaires synthétisées
Formalisation des axes de développement
Génération automatique d’un prompt personnalisé (étape 7) à utiliser avec une IA pour obtenir des
pistes
d’amélioration
Concrètement, il s'agit de compiler sans les mettre en forme, au format pdf de préférence, toutes les
informations dont vous disposez (récoltées ou générées par les outils proposés) et de les enrichir de
notes
complémentaires. Un prompt adapté sera généré.
Ce prompt ainsi que vos documents seront ajoutés à l'IA de
votre choix (au moins deux conseillées) et produiront une analyse, des pistes, un résumé pour le CA etc.
Attention : Les données ne sont pas stockées en ligne (sauf sauvegarde manuelle possible dans votre
navigateur). L’IA génère des suggestions à valider et adapter par le documentaliste.
Ne transmettez jamais de données personnelles à une IA (sauf si elle est garantie conforme au RGPD).
Cette mini application est aussi un support de formation que nous utilisons
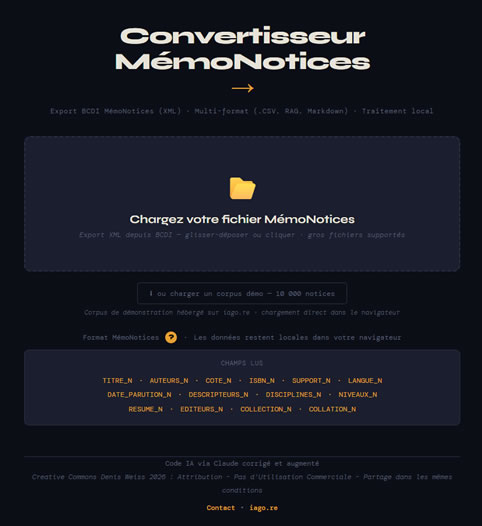
 Lien vers le convertisseur en ligne
Lien vers le convertisseur en ligne














 Pour Arthur Perret "ChatGPT ne vous dit pas tout". Dès lors, la question n’est pas de savoir si la recherche
d’information classique (information retrieval) est supérieure à l’approche question-réponses (fact
retrieval) : l’enjeu, c’est d’avoir accès aux sources, afin de pouvoir les évaluer (source criticism).
Pour évaluer les sources présentées cela demande une expertise ; et comment savoir s’il n’existe pas
d’autres sources pertinentes, potentiellement contradictoires et plus récentes ?
Pour Arthur Perret "ChatGPT ne vous dit pas tout". Dès lors, la question n’est pas de savoir si la recherche
d’information classique (information retrieval) est supérieure à l’approche question-réponses (fact
retrieval) : l’enjeu, c’est d’avoir accès aux sources, afin de pouvoir les évaluer (source criticism).
Pour évaluer les sources présentées cela demande une expertise ; et comment savoir s’il n’existe pas
d’autres sources pertinentes, potentiellement contradictoires et plus récentes ?