Machine learning
Pour qu'un ordinateur puisse reconnaître un texte, une image ou un son, il doit d'abord s'entraîner, c'est le « machine learning » ou « apprentissage supervisé. »
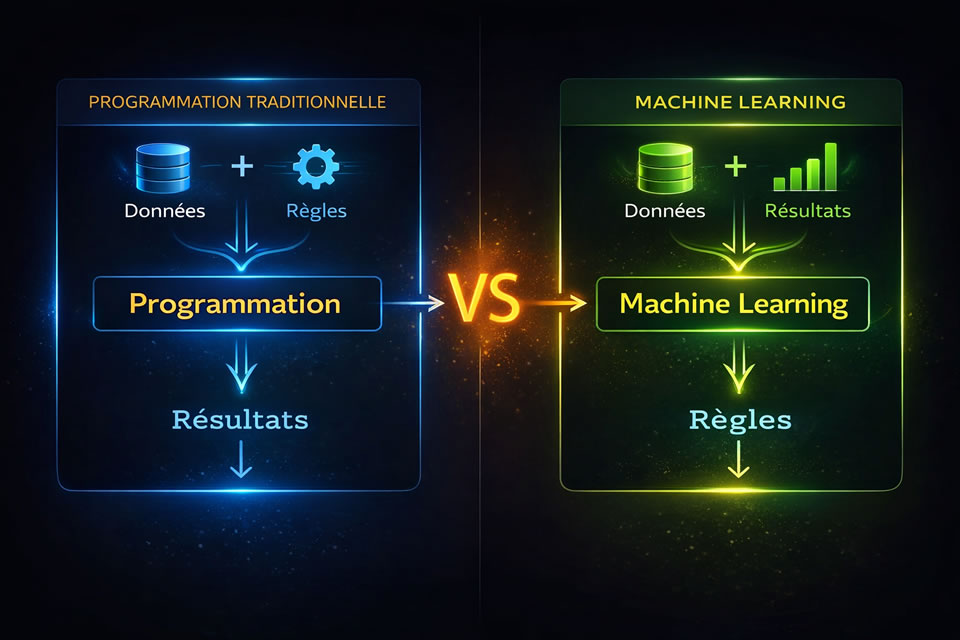
Pour cela, on va lui soumettre d'immenses quantités de données, de préférence de type image / description, l'on parle d'images catégorisées ou de traductions vérifiées.
Vous comprenez ici mieux pourquoi l'on vous demande souvent de mettre un nom sur un visage.
Sur
"copains d'avant" ou Facebook, c'est d'abord vous et pas une quelconque IA qui est le meilleur
informateur.
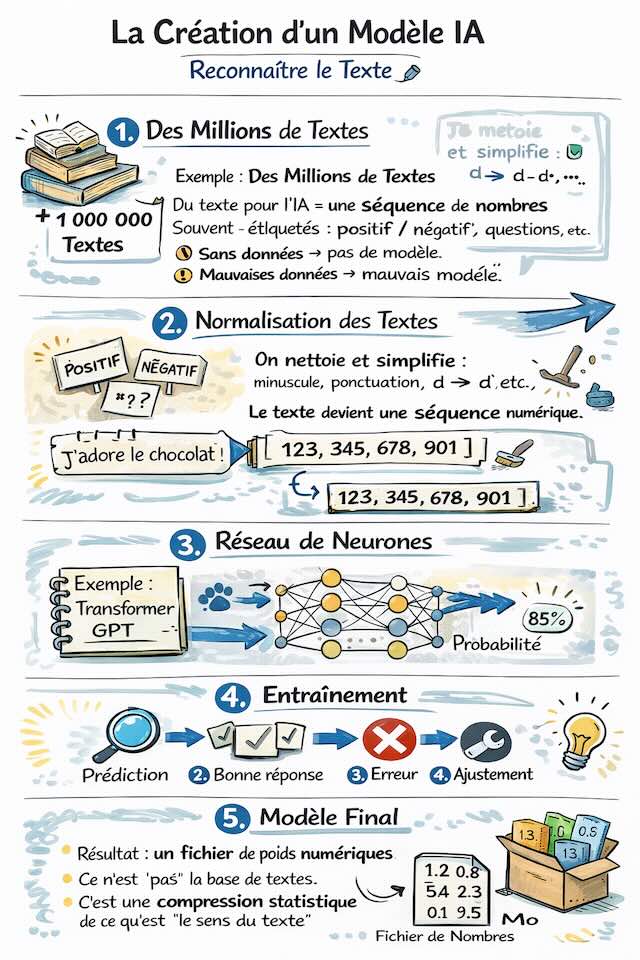
La recette d'un modèle IA
 voir en pleine page
voir en pleine page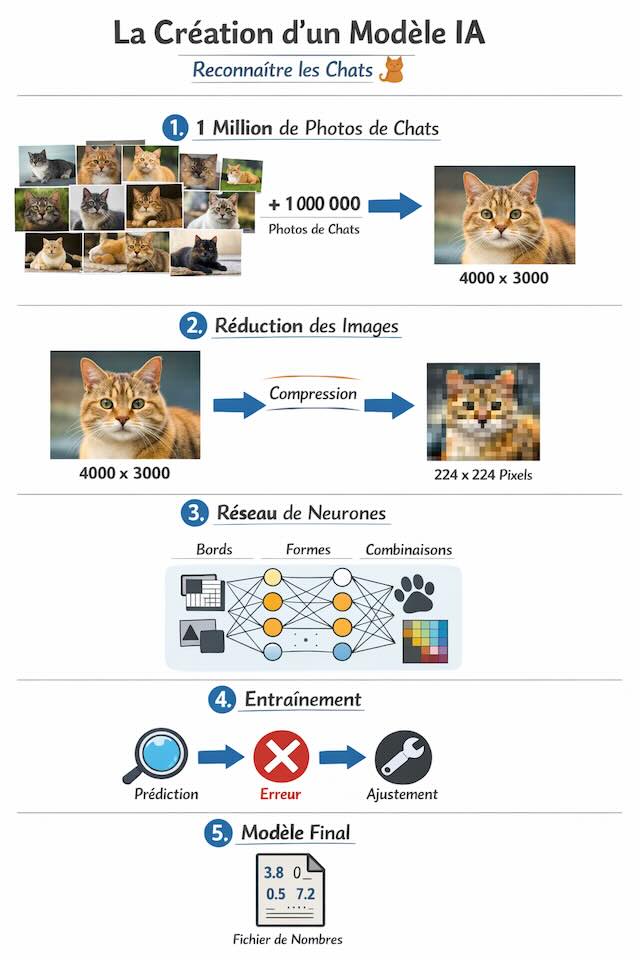


2017 : TeachMachine

 Pour
en savoir plus
Pour
en savoir plusVoir également le site fr.vittascience.com/
Les 4 étapes pour entrainer un LLM
Qu'est-ce qu'a bien pu faire la start-up chinoise DeepSeek pour secouer le monde de la tech ? Pour le comprendre, on se demande comment passer d'un simple compléteur de texte, à un assistant IA capable de raisonner !
Pour tout savoir sur les LLM en 3h 30, une vidéo en anglais d'Andrej Karpathy, un informaticien slovaco-canadien qui a été directeur de l'intelligence artificielle et du pilotage automatique chez Tesla.
 www.youtube.com/watch?v=7xTGNNLPyMI
www.youtube.com/watch?v=7xTGNNLPyMI
L'illusion de la réalité
On pense, souvent un peu vite, que la réalité est une donnée que nous percevons, oubliant par-là que c'est d'abord une construction de notre cerveau.







Pour réaliser ce que vous faites ici facilement, une IA doit analyser des milliers et des milliers voire des millions de visages catégorisés.
Par exemple pour reconnaître un chat il faut plusieurs dizaines de milliers de photos de chats identifiés comme tels.

Il existe des dataset libres de droits que l'on peut télécharger.
Par exemple ici pour accéder à 29 843 images couleur de chats, résolution 64x64 pixels, licence MIT.
Vous pouvez ainsi télécharger des images de vidéo, audio, du texte, médical etc.
Le test de Turing
 Dans son
article de 1950, Alan Turing
affirmait que les systèmes d’IA seraient un jour si performants au jeu de l’imitation
humaine
qu’un
interrogateur humain n’aurait pas plus de 70 % de chances de faire la différence entre la
machine et
l’humain en 5 minutes d’interaction.
Dans son
article de 1950, Alan Turing
affirmait que les systèmes d’IA seraient un jour si performants au jeu de l’imitation
humaine
qu’un
interrogateur humain n’aurait pas plus de 70 % de chances de faire la différence entre la
machine et
l’humain en 5 minutes d’interaction.
Autrement dit, pour qu’une machine passe le test de
Turing,
elle doit obtenir un score de 30 %.
Dans une expérience, 500 participants sont divisés en 4 groupes dont l’un devait discuter avec un humain. Les conversations ont duré cinq minutes. Les participants devaient ensuite annoncer si leur interlocuteur était selon eux humain ou non.
Les taux de réussite étaient les suivants :
- ELIZA => 22 % des cas
- GPT-3.5 => 50%
- GPT-4 => 54%
- Participant humain => 67%
Les machines de Turing
Les machines de Turing, un des fondements théoriques des ordinateurs modernes, qui permettent de montrer qu'en un certain sens, tous les ordinateurs de l'Univers se valent.
Pour tester les IA (Benchmark), l'on peut aussi avoir recourt a divers jeux de tests. En voici quelques-uns :
- Maths : GSM8K est un ensemble de données de 85 000 problèmes de mathématiques

- En maths voir également FrontierMath
- MMLU :Measuring Massive Multitask Language Understanding est un test de performance
pour
évaluer les capacités des grands modèles de langage
- NLF Perf, les benchmark de Nvidia!!! pour produire des évaluations impartiales des
performances
d'entraînement et d'inférence pour le matériel, les logiciels et les services.
- TruthfulQA : 817 questions couvrant 38 catégories, dont la santé, le droit, la finance
et
la politique.
Dernier examen de l'humanité
Le "Dernier examen de l'humanité" (Humanity's Last Exam - HLE) est un benchmark révolutionnaire développé conjointement par Scale AI et le Center for AI Safety (CAIS), conçu pour tester les limites de la connaissance de l'IA aux frontières de l'expertise humaine SafeScale. Il s'agit d'un benchmark multimodal comprenant 2 500 questions difficiles réparties sur plus d'une centaine de sujets académiques.
La répartition est la suivante. Mathématiques (41%), physique (9%), biologie/médecine (11%), sciences humaines/sociales (9%), informatique/IA (10%), ingénierie (4%), chimie (7%), et autres (9%). Chaque question a une solution connue, non ambiguë et facilement vérifiable, mais ne peut pas être résolue rapidement par une recherche internet.
Ce benchmark soulève des questions fondamentales sur l'avenir de l'éducation :
- Si l'IA peut maîtriser les connaissances expertes les plus pointues, quel reste-t-il comme domaine réservé à l'apprentissage humain ?
- Comment redéfinir les objectifs éducatifs face à des machines potentiellement omniscientes ?
- Le "dernier examen" marque-t-il symboliquement la fin d'une ère où l'évaluation cognitive humaine avait un sens ?
Plus qu'un simple benchmark technique, c'est un marqueur civilisationnel qui interroge la place de l'intelligence humaine dans un monde où l'IA pourrait bientôt surpasser nos meilleures performances intellectuelles.
Êtes-vous un robot ?
Cette phrase, vous la voyez assez régulièrement, accompagnée d'un CAPTCHA ou “Completely Automated Public Turing test to tell Computers and Humans Apart”, autrement une variante de tests de Turing permettant de différencier de manière automatisée un utilisateur humain d'un ordinateur. Ce test de défi-réponse est utilisé en informatique pour vérifier que l'utilisateur n'est pas un robot.
 Dans
la
première version, l'on vous
demandait de reconnaître des lettres. Sauf que très vite les robots les reconnaissaient
aussi.
Sont alors arrivées les photos de rues et de feu rouges.
Dans
la
première version, l'on vous
demandait de reconnaître des lettres. Sauf que très vite les robots les reconnaissaient
aussi.
Sont alors arrivées les photos de rues et de feu rouges.
Notons ici que vous travaillez gratuitement pour enrichir la base de connaissance des IA, notamment en matière de conduite automobile en résolvant des problèmes difficiles à résoudre pour un robot. Du "machine learning" à votre insu.
Combien de cases de passages piétons auriez-vous coché ?

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
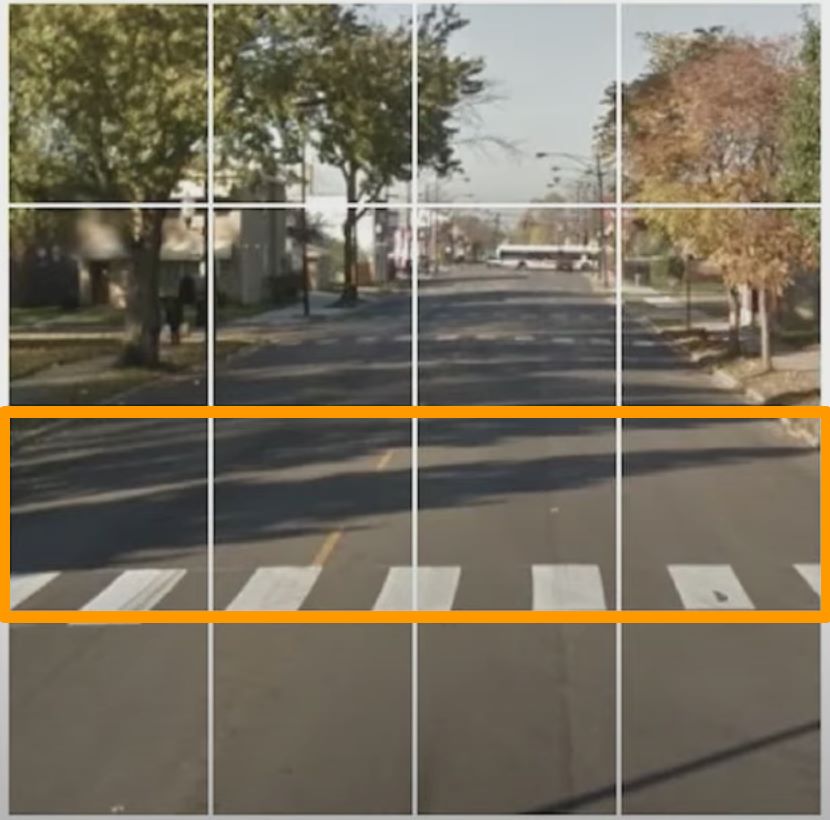
Mais vous auriez aussi très bien pu cocher 9 ou 10 cases, ce qui serait plus conforme à la réalité.
Bravo ! Vous n'êtes pas un 🤖 !
 Ce
CAPTCHA tend à disparaître au profit
d'une simple case à cocher. Simple, n'est pas ici exactement le mot, puisque que c'est
la
manière même (temps, déplacement de la souris etc.) qui va déterminer si vous êtes un
humain.
Ce
CAPTCHA tend à disparaître au profit
d'une simple case à cocher. Simple, n'est pas ici exactement le mot, puisque que c'est
la
manière même (temps, déplacement de la souris etc.) qui va déterminer si vous êtes un
humain.
Ce dernier type de vérification va d'ailleurs aussi être remplacé par une analyse de comportement face à l'écran.
Ce sera la fin du CAPTCHA.
 La base de
données MNIST pour "Modified ou Mixed National Institute of Standards and
Technology",
est
une base de données de chiffres écrits à la main. C'est un jeu de données très
utilisé
en
apprentissage automatique.
La base de
données MNIST pour "Modified ou Mixed National Institute of Standards and
Technology",
est
une base de données de chiffres écrits à la main. C'est un jeu de données très
utilisé
en
apprentissage automatique.
La reconnaissance de l'écriture manuscrite est un problème difficile, et un bon test pour les algorithmes d'apprentissage. La base MNIST est devenue un test standard. Elle regroupe 60 000 images d'apprentissage et 10000 images de test.
Mais avant d'aspirer tout le web, cela a commencé bien plus modestement.
How we teach computers to understand pictures | Fei Fei Li
Quand un tout jeune enfant regarde une photo, il peut identifier des éléments simples : un chat, un livre, une chaise. Aujourd'hui, les ordinateurs sont assez intelligents pour faire la même chose. Et après ? Dans cette passionnante conférence, la spécialiste en vision par ordinateur Fei-Fei Li décrit où nous en sommes : la base de données de 15 millions de photos mise en place par son équipe pour « enseigner » à un ordinateur à comprendre des photos, et un aperçu de ce qui reste encore à faire.

Surgemini.google.com/appcopiez-collez le prompt suivant


Voir également
Les images/vidéos avec l'IA : comment ça marche ?
Modèles de diffusion, CLIP et les mathématiques qui permettent de transformer du texte en images.
Computer Scientist Explains Machine Learning in 5 Levels of Difficulty | WIRED
WIRED has challenged computer scientist and Hidden Door cofounder and CEO Hilary Mason to explain machine learning to 5 different people; a child, teen, a college student, a grad student and an expert.
Hilary Mason, informaticienne, expliquer l’apprentissage automatique en cinq niveaux de complexité croissante.Niveau 1 : Enfant (Brynn)
L’apprentissage automatique nous permet d’apprendre des choses sur le monde à partir de grandes quantités de données que nous, êtres humains, ne pourrions jamais étudier ou comprendre.
L’apprentissage automatique, c’est une façon d’apprendre aux ordinateurs comprendre des choses sur le monde en observant des exemples : Chien, chat, humain. Donc, l’apprentissage automatique, c’est quand on apprend aux machines à faire des suppositions sur ce que sont les choses en se basant sur l’observation de nombreux exemples différents.
On doit leur montrer des dizaines de milliers voire des millions d’exemples avant qu’elles ne deviennent aussi bonnes que toi.
Niveau 2 : Collégienne (Lucy)
Je vais supposer que ça signifie que les humains peuvent apprendre aux machines ou aux robots à apprendre par eux-mêmes ? C’est ça. Quand on apprend aux machines à apprendre à partir de données, à construire un modèle à partir de ces données ou une représentation de celles-ci, et ensuite à faire une prédiction.
Pour faire de l’apprentissage automatique, on utilise quelque chose qu’on appelle des algorithmes. C’est une série d’étapes ou un processus réalisé pour accomplir quelque chose ?
Les humains sont vraiment doués pour apprendre quelque chose de nouveau avec seulement un ou deux exemples et l’intégrer à notre modèle du monde pour prendre de bonnes décisions. Alors que les machines ont souvent besoin de dizaines de milliers d’exemples. Les machines sont douées pour prédire en se basant sur ce qu’elles ont vu dans le passé, mais elles ne sont pas créatives.
Niveau 3 : Étudiante en informatique (Sunny)
Comment ferais-tu pour classer un email ? — Je regarderais les mots-clés, l’expéditeur, les emails précédents… — Ce sont des features (caractéristiques). En apprentissage supervisé, on choisit ces features à la main. En non supervisé, la machine les découvre toute seule, comme des groupes de données similaires. Le deep learning utilise des réseaux de neurones pour analyser des montagnes de données, mais parfois, une simple régression linéaire suffit. — Et si on choisit la mauvaise méthode ? — On peut obtenir un système précis mais inutile. Par exemple, un modèle qui prédit les désabonnements sans expliquer pourquoi. L’important, c’est de comprendre pourquoi la machine prend une décision.
Niveau 4 : Doctorante en NLP
Je compare le deep learning (pour extraire des features automatiquement) et les méthodes traditionnelles comme les lexiques. Le deep learning est puissant, mais moins interprétable. Par exemple, les modèles comme GPT-3 peuvent générer des textes grammaticaux, mais ils reproduisent aussi les biais présents dans les données d’entraînement.
Comment mesurer ces biais ? — On peut tester des prompts comme "La femme était…" vs "L’homme était…" pour voir les différences de réponses. Mais c’est complexe : les modèles ne sont pas transparents. Il faut documenter les limites des données et être honnête sur les risques.
Niveau 5 : Experte (Claudia)
Dans la santé, les données manquent souvent ou sont biaisées. — Oui, et ces biais sont amplifiés par les algorithmes. Par exemple, en publicité, les données sur nos habitudes sont utilisées pour cibler des annonces. Mais qui décide de l’éthique ? Le vrai défi, c’est d’appliquer ces outils aux vrais problèmes, pas seulement aux plus rentables.
Es-tu optimiste pour l’avenir ? — Oui ! Malgré les risques, l’IA peut réduire les dommages et aider à prendre de meilleures décisions. Mais il faut des garde-fous : transparence, documentation des données, et une réflexion sur l’impact sociétal.
Generative Adversarial Network (GAN)
Le Generative Adversarial Network (GAN) ou réseaux antagonistes génératifs (RAG) sont une classe d'algorithmes d'apprentissage non supervisé.
L'apprentissage non supervisé désigne la situation d'apprentissage automatique où les données ne sont pas étiquetées (par exemple étiquetées comme « pouce » ou « Le Carnaval d’Arlequin. Peinture de Joan Miró »).
Un GAN est un modèle génératif où deux réseaux sont placés en compétition dans un scénario de
théorie
des jeux. Le premier réseau est le générateur, il génère un échantillon (ex. une image),
tandis
que
son adversaire, le discriminateur essaie de détecter si un échantillon est réel ou bien s'il
est
le
résultat du générateur.
Ainsi, le générateur est entrainé avec comme but de tromper le
discriminateur.
Comment ces IA inventent-elles des images ?
Qu'est-ce qu'a bien pu faire la start-up chinoise DeepSeek pour secouer le monde
de
la
tech ?
Pour le comprendre, on se demande comment passer d'un simple
compléteur
de texte, à un assistant IA capable de raisonner !
Les 4 étapes pour entrainer un LLM
Stable Diffusion, Midjourney ou DALLE 2.
Le principe de ces algorithmes
d'intelligence
artificielle qui savent générer des images à partir d'un texte.
Réseau de neurones

Les réseaux de neurones, également connus sous le nom de réseaux de neurones artificiels
(ANN) ou
réseaux de neurones simulés (SNN) sont constitués de couches nodales, contenant une couche
d'entrée,
une ou plusieurs couches cachées et une couche de sortie.
Chaque nœud, ou neurone
artificiel,
se
connecte à un autre et possède un poids et un seuil associés. Si la sortie d'un nœud est
supérieure
à la valeur de seuil spécifiée, ce nœud est activé et envoie des données à la couche
suivante du
réseau. Sinon, aucune donnée n'est transmise à la couche suivante du réseau.
Les réseaux de neurones s'appuient sur des données d'entraînement pour apprendre et améliorer leur précision au fil du temps.
Quatre des applications importantes des réseaux neuronaux.
- Reconnaissance d'image : C'est la capacité des ordinateurs à extraire des informations et des idées à partir d'images et de vidéos
- Reconnaissance vocale : Ce sont les assistants virtuels comme Amazon Alexa ou Siri
- Traitement du langage naturel : Ce sont les Agents virtuels et chatbots du type chatGPT
- Moteurs de recommandation : C'est par exemple le suivis des activités des utilisateurs pour élaborer des recommandations personnalisées.
Algorithme de rétropropagation
Les réseaux neuronaux artificiels apprennent en permanence en utilisant des boucles de
rétroaction corrective pour améliorer leur analytique prédictive.
En termes simples,
vous
pouvez imaginer que les données circulent du nœud d'entrée au nœud de sortie par
plusieurs
chemins différents dans le réseau neuronal. Un seul chemin est le chemin correct qui
relie
le
nœud d'entrée au nœud de sortie correct. Pour trouver ce chemin, le réseau neuronal
utilise
une
boucle de rétroaction, qui fonctionne comme suit :
- Chaque nœud fait une supposition sur le prochain nœud du chemin.
- Il vérifie si la supposition était correcte. Les nœuds attribuent des valeurs de poids plus élevées aux chemins qui mènent à un plus grand nombre de suppositions correctes et des valeurs de poids plus faibles aux chemins de nœuds qui mènent à des suppositions incorrectes.
- Pour le point de données suivant, les nœuds effectuent une nouvelle prédiction en utilisant les chemins de poids plus élevé, puis répètent l'étape 1.
Apprentissage supervisé
Dans l'apprentissage supervisé, les réseaux de neurones "s'entrainent" sur des jeux de
données
étiquetés qui fournissent la bonne réponse à l'avance.
Par exemple, un réseau de deep
learning s'entraînant à la reconnaissance faciale traite initialement des centaines de
milliers
d'images de visages humains, avec divers termes liés à l'origine ethnique, au pays ou à
l'émotion décrivant chaque image.
Les Transformers
Ce sont une famille particulière de réseaux de neurones apparus en 2017. Les types courants de réseaux de neurones permettent de traiter les données simples (MLP (dense)), les images, la vision (CNN, GAN), les données séquentielles (RNN / LSTM / GRU). Les Transformers concernent le texte et sont multimodaux.
Comprendre Les Transformers en Moins de 20 Min : Guide Pour Débutants
Introduction aux Transformers : Historique et contexte, Tokenisation et Embedding, Encoder et Decoder, Pourquoi les transformers ? Structure et fonctionnement basique, Mécanisme d'attention, Attention Multi-Tête, Encoder des transformers, Quiz et conclusion.
Testez vos connaissances
Débusquer l'IA
En coproduction avec l'INRIA et S24B, une série d'exercices et de vidéos pour mieux comprendre le fonctionnement de l'IA.