
IA en classe | Machine learning
Pour qu'un ordinateur puisse reconnaître un texte, une image ou un son, il doit d'abord s'entraîner, c'est le « machine learning ».
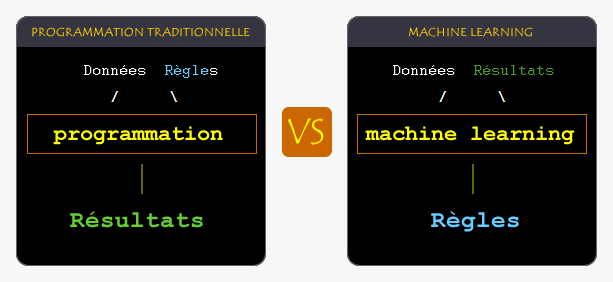
Pour cela, on va lui soumettre d'immenses quantités de données, de préférence de type image / description, l'on parle d'images catégorisées ou de traductions vérifiées.
Vous comprenez ici mieux pourquoi l'on vous demande souvent de mettre un
nom sur un visage.
Sur "copains d'avant" ou Facebook, c'est d'abord vous et pas une
quelconque IA
qui est le meilleur informateur.

Ce modèle a été entrainé sur https://teachablemachine.withgoogle.com/ à partir de quelques images de gestes de plongée. Le modèle permet ensuite d'évaluer le taux de compatibilité du geste. Vous pouvez entraîner un ordinateur à reconnaître vos propres images, sons et postures.
Voir également un exemple de poule ou coq, ou lendormi ou margouillat.
 Pour en savoir plus
Pour en savoir plus
L'IA et ses défis - Colloque au Collège de France : extrait, le machine learning
Extrait du colloque conjointement diffusé le 28 sept. 2023 par le Campus de
l’Innovation
pour les Lycées et par Sciences Po, ce colloque propose de nous interroger sur
l’intelligence artificielle et les nombreux défis qu’elle nous impose. Il s'adresse
principalement aux élèves de première et terminale issus des réseaux d'éducation
prioritaire.
Partie extraite. Benoît Sagot, directeur de recherche à l’Inria et professeur invité
à
occuper la chaire annuelle Informatique et sciences numériques du Collège de France,
nous initiera à « L’apprentissage profond, au cœur de l’IA moderne ».

L'illusion de la réalité
On pense, souvent un peu vite, que la réalité est une donnée que nous percevons, oubliant par-là que c'est d'abord une construction de notre cerveau.









Pour réaliser ce que vous faites ici facilement, une IA doit analyser des milliers et des milliers voire des millions de visages avec un nom.
Par exemple pour reconnaître un chat il faut plusieurs dizaines de milliers de photos de chats identifiés comme tels.

Êtes-vous un robot ?
Cette phrase, vous la voyez assez régulièrement, accompagnée d'un CAPTCHA ou “Completely Automated Public Turing test to tell Computers and Humans Apart”, autrement une variante de tests de Turing permettant de différencier de manière automatisée un utilisateur humain d'un ordinateur. Ce test de défi-réponse est utilisé en informatique pour vérifier que l'utilisateur n'est pas un robot.
 Dans
la première version, l'on vous
demandait de reconnaître des lettres. Sauf que très vite les robots les reconnaissaient
aussi. Sont alors arrivées les photos de rues et de feu rouges.
Dans
la première version, l'on vous
demandait de reconnaître des lettres. Sauf que très vite les robots les reconnaissaient
aussi. Sont alors arrivées les photos de rues et de feu rouges.
Notons ici que vous travaillez gratuitement pour enrichir la base de connaissance des IA, notamment en matière de conduite automobile en résolvant des problèmes difficiles à résoudre pour un robot. Du "machine learning" à votre insu.
Combien des cases de passages piétons auriez-vous coché ?

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
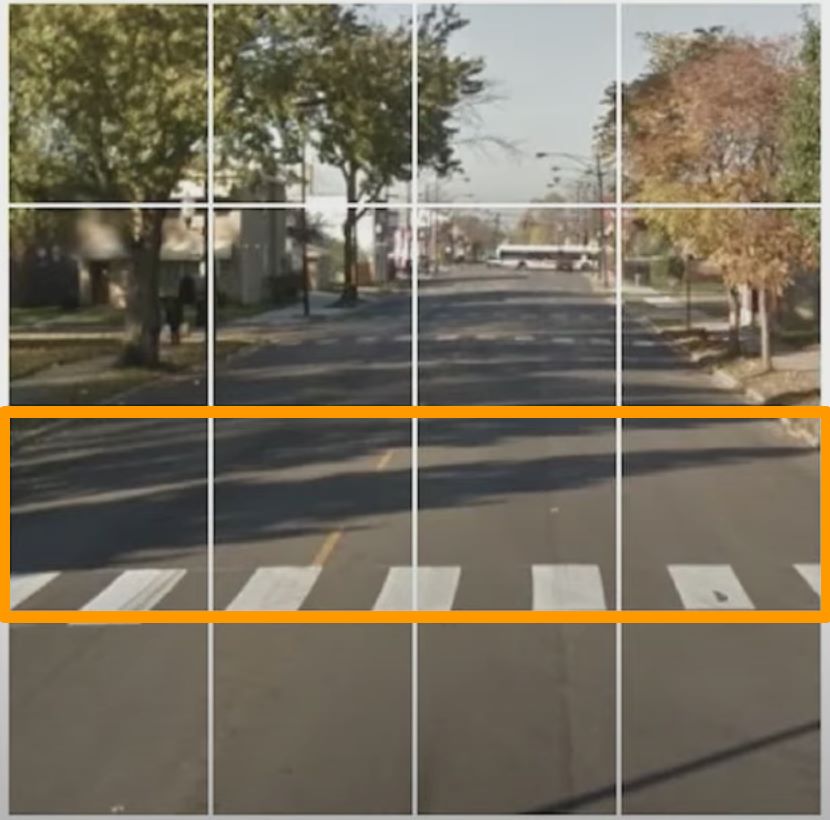
Mais vous auriez aussi très bien pu cocher 9 ou 10 cases, ce qui serait plus conforme à la réalité.
Bravo ! Vous n'êtes pas un 🤖 !
 Ce
CAPTCHA tend à disparaître au profit d'une
simple case à cocher. Simple, n'est pas ici exactement le mot, puisque que c'est la manière
même (temps, déplacement de la souris etc.) qui va déterminer si vous êtes un humain.
Ce
CAPTCHA tend à disparaître au profit d'une
simple case à cocher. Simple, n'est pas ici exactement le mot, puisque que c'est la manière
même (temps, déplacement de la souris etc.) qui va déterminer si vous êtes un humain.
Ce dernier type de vérification va d'ailleurs aussi être remplacé par une analyse de comportement face à l'écran.
Ce sera la fin du CAPTCHA.

 La
base de données MNIST pour "Modified ou
Mixed
National Institute of Standards and Technology", est une base de données de chiffres
écrits
à la
main. C'est un jeu de données très utilisé en apprentissage automatique.
La
base de données MNIST pour "Modified ou
Mixed
National Institute of Standards and Technology", est une base de données de chiffres
écrits
à la
main. C'est un jeu de données très utilisé en apprentissage automatique.
La reconnaissance de l'écriture manuscrite est un problème difficile, et un bon test pour les algorithmes d'apprentissage. La base MNIST est devenue un test standard. Elle regroupe 60 000 images d'apprentissage et 10000 images de test.
How we teach computers to understand pictures | Fei Fei Li
Quand un tout jeune enfant regarde une photo, il peut identifier des éléments simples : un chat, un livre, une chaise. Aujourd'hui, les ordinateurs sont assez intelligents pour faire la même chose. Et après ? Dans cette passionnante conférence, la spécialiste en vision par ordinateur Fei-Fei Li décrit où nous en sommes : la base de données de 15 millions de photos mise en place par son équipe pour « enseigner » à un ordinateur à comprendre des photos, et un aperçu de ce qui reste encore à faire.
Sur https://gemini.google.com/app copiez-collez le prompt suivant
https://www.youtube.com/watch?v=40riCqvRoMs Résumé de cette conférence en 30 lignes…

Le Generative Adversarial Network (GAN) ou réseaux antagonistes génératifs (RAG) sont une classe d'algorithmes d'apprentissage non supervisé.
L'apprentissage non supervisé désigne la situation d'apprentissage automatique où les données ne sont pas étiquetées (par exemple étiquetées comme « pouce » ou « Le Carnaval d’Arlequin. Peinture de Joan Miró »).
Un GAN est un modèle génératif où deux réseaux sont placés en compétition dans un scénario de
théorie des jeux. Le premier réseau est le générateur, il génère un échantillon (ex. une
image),
tandis que son adversaire, le discriminateur essaie de détecter si un échantillon est réel
ou
bien s'il est le résultat du générateur.
Ainsi, le générateur est entrainé avec comme but
de
tromper le discriminateur.
Comment ces IA inventent-elles des images ?
Stable Diffusion, Midjourney ou DALLE 2. Le principe de ces algorithmes d'intelligence artificielle qui savent générer des images à partir d'un texte.

Les réseaux de neurones, également connus sous le nom de réseaux de neurones artificiels
(ANN)
ou
réseaux de neurones simulés (SNN) sont constitués de couches nodales, contenant une couche
d'entrée,
une ou plusieurs couches cachées et une couche de sortie.
Chaque nœud, ou neurone
artificiel, se
connecte à un autre et possède un poids et un seuil associés. Si la sortie d'un nœud est
supérieure
à la valeur de seuil spécifiée, ce nœud est activé et envoie des données à la couche
suivante du
réseau. Sinon, aucune donnée n'est transmise à la couche suivante du réseau.
Les réseaux de neurones s'appuient sur des données d'entraînement pour apprendre et améliorer leur précision au fil du temps.
www.ibm.com/
aws.amazon.com/
Quatre des applications importantes des réseaux neuronaux.
- Reconnaissance d'image : C'est la capacité des ordinateurs à extraire des informations et des idées à partir d'images et de vidéos
- Reconnaissance vocale : Ce sont les assistants virtuels comme Amazon Alexa ou Siri
- Traitement du langage naturel : Ce sont les Agents virtuels et chatbots du type chatGPT
- Moteurs de recommandation : C'est par exemple le suivis des activités des utilisateurs pour élaborer des recommandations personnalisées.
Algorithme de rétropropagation
Les réseaux neuronaux artificiels apprennent en permanence en utilisant des boucles de
rétroaction corrective pour améliorer leur analytique prédictive.
En termes simples,
vous
pouvez
imaginer que les données circulent du nœud d'entrée au nœud de sortie par plusieurs
chemins
différents dans le réseau neuronal. Un seul chemin est le chemin correct qui relie le
nœud
d'entrée au nœud de sortie correct. Pour trouver ce chemin, le réseau neuronal utilise
une
boucle de rétroaction, qui fonctionne comme suit :
- Chaque nœud fait une supposition sur le prochain nœud du chemin.
- Il vérifie si la supposition était correcte. Les nœuds attribuent des valeurs de poids plus élevées aux chemins qui mènent à un plus grand nombre de suppositions correctes et des valeurs de poids plus faibles aux chemins de nœuds qui mènent à des suppositions incorrectes.
- Pour le point de données suivant, les noeuds effectuent une nouvelle prédiction en utilisant les chemins de poids plus élevé, puis répètent l'étape 1.
Apprentissage supervisé
Dans l'apprentissage supervisé, les réseaux de neurones "s'entrainent" sur des jeux de
données
étiquetés qui fournissent la bonne réponse à l'avance.
Par exemple,
un réseau de deep learning s'entraînant à la reconnaissance faciale traite initialement
des
centaines de milliers d'images de visages humains, avec divers termes liés à l'origine
ethnique,
au pays ou à l'émotion décrivant chaque image.
Débusquer l'IA
En coproduction avec l'INRIA et S24B, une série d'exercices et de vidéos pour mieux comprendre le fonctionnement de l'IA.