
IA en classe | Text to…
C'est l'essence même de l'IA. Partir d'une requête textuelle (un prompt) et générer quelque chose…

Un grand classique de l'IA, popularisé notamment par Siri (2011) ou Alexa (2014) pour les instructions par reconnaissance vocale.
Le traitement du langage naturel est une avancée récente dans le domaine de la reconnaissance vocale, et permet à l'IA de s'appuyer sur les règles grammaticales pour analyser des discours en direct.
Exemple : GoSpeech
L'application GoSpeech permet de générer le texte d'un fichier audio enregistré (limité à 3 fichiers de 10 minutes chacun en version gratuite).

Amazon Transcribe Medical est un outil permettant aux professionnels de la santé d'enregistrer rapidement et efficacement des conversations cliniques dans des systèmes de dossiers de santé électroniques à des fins d'analyse. Par exemple, dans le secteur bancaire, la synthèse vocale est utilisée via un service client activé par la voix. Dans le secteur de la santé, la synthèse vocale contribue à améliorer l'efficacité en fournissant un accès immédiat aux informations et en saisissant des données.
Processus inverse, il s'agit de faire parler la machine en lui soumettant un texte. Rire et voix d'enfants sont les plus difficile à reproduire.
Les résultats sont de plus en plus convaiquents.
Voici le texte qui est proposé, ensuite enregistré via un téléphone.

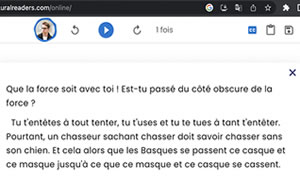
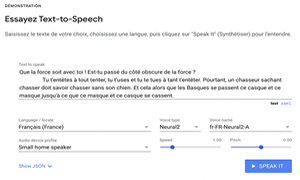
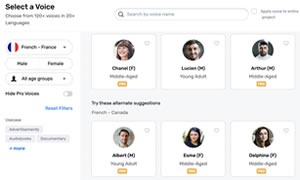
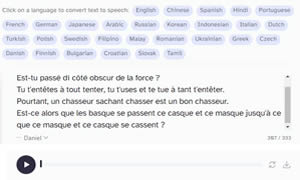
Dans la série des outils d'openai, Whisper est un système de reconnaissance vocale automatique passé en opensource (ASR) formé sur 680 000 heures de données supervisées multilingues et multitâches collectées sur le Web.
Whisper est le nom du réseau de neurones utilisé. Il est proposé sur github pour les codeurs.
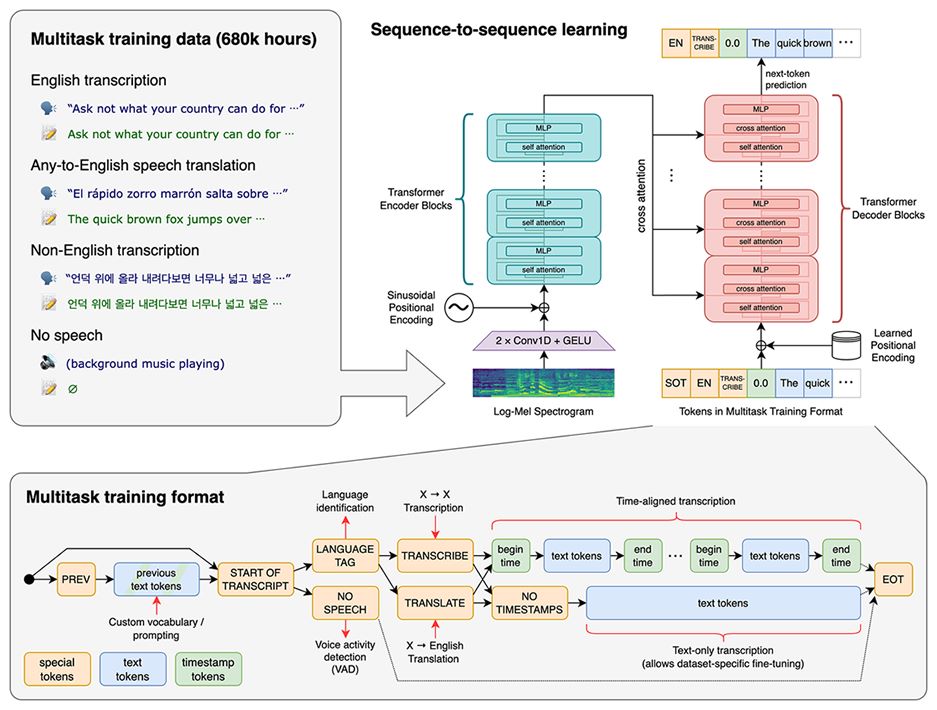
Dans le même esprit, assemblyAI propose une API très simple aux codeurs. Avec quelques lignes de code, par exemple en Python avec vos élèves, un fichier son peut lui être fournit en entrée pour disposer de sa transcription en sortie.
Voir également elevenlabs.io/
Tales audio
Dans l'exemple ci-dessous, les voix ont été entrainées à partir d'échantillons divers notamment en chinois. Le plus difficile, reproduire les voix des enfants ou les rires. Un comédien peu donc produire tout seul toutes les voix.
Entrainer les modèles de voix à partir des échantillons nécessite de grosse puissances de calculs (confiées aux cartes graphiques) ou via la location d'une instance de machine virtuelle en ligne. L'écriture du scénario est assistée par un moteur de développement de jeux vidéos
Whisper va générer automatiquement les sous-titres.
Les voix, notamment, mais aussi les illustations sont générés par l'IA et/ou des "Modificateur de voix".
Le résultat peut être "écouté" en cliquant sur l'image ci-dessous. Tales Audio propose des fictions audio Immersives sur le thème du fantastique, de l'horreur et de la SF.
Podcast automatique
Perplexity propose désormais un podcast sur les derniers développements en matière de technologie, de science et de culture. Discover Daily vous tient informé des tendances et des idées qui façonnent notre avenir en s'appuyant sur la recherche de Perplexity et la voix IA d'ElevenLabs.
 www.perplexity.ai/podcast
www.perplexity.ai/podcast
Le site voicemod permet de générer une musique à partir de n'importe quel texte en sélectionnant une voix, un style etc.
Voir également

Outre Midjourney, une application payante (après 25 images gratuites à la date de rédaction, 9€) devenue célèbre pour ses faux notamment d'un ex président américain, il existe de nombreux sites qui permettent de transformer une commande textuelle, le fameux prompt, en image.

Outre le très connu ChatGPT, openai.com/ propose également une application plus ancienne et non moins performant, Dall-e-2.

Le site nightcafe propose des crédits gratuits pour réaliser des images à partir de différents modèles Stable Diffusion, SDXL.




L’approche guidée par CLIP avec dream.ai est un réseau de neurones open source créé par l’équipe de recherche d’OpenAI.

Un sérieux concurrent de Midjourney, 100 images gratuites par jour au moment de la rédaction.



Tracer des graphiques
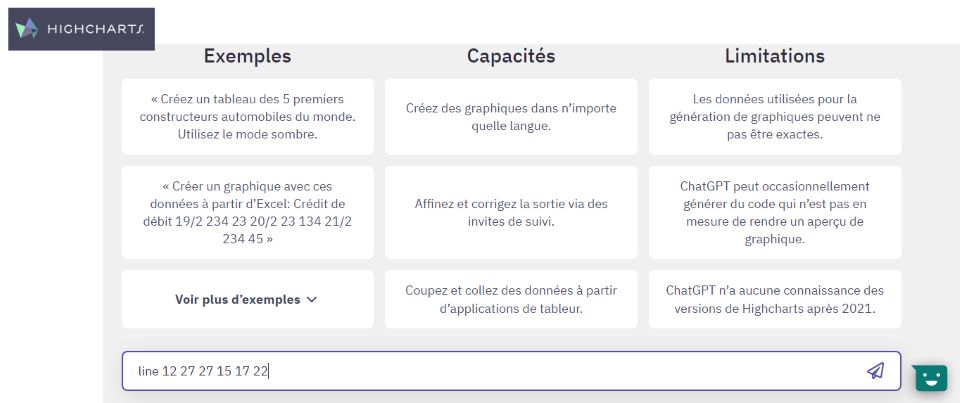
La bibliothèque très connue higcharts.com propose de réaliser, avec le code, des graphiques à partir de données aussi simples que "line 12 47 23 35", ou alors bien plus complexes.
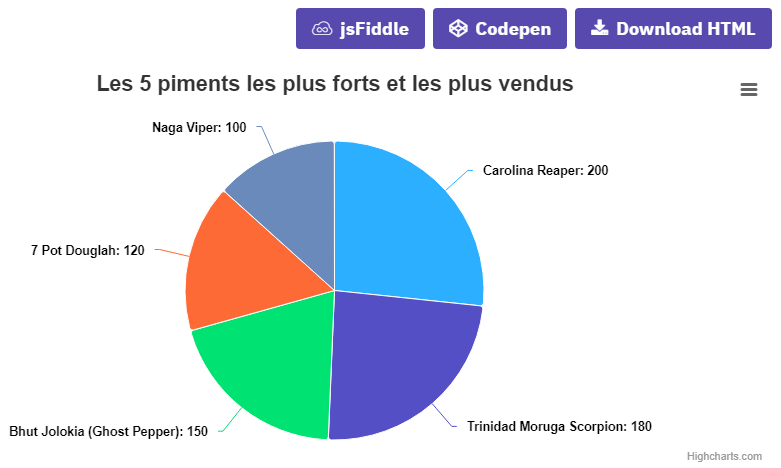
Camembert des 5 piments les plus forts et les plus vendus
Evidement Adobe ne pouvait pas rester les bras croisés et propose de nombreuses fonctions, souvent en version bêta pour l'instant, mais prometteuses.
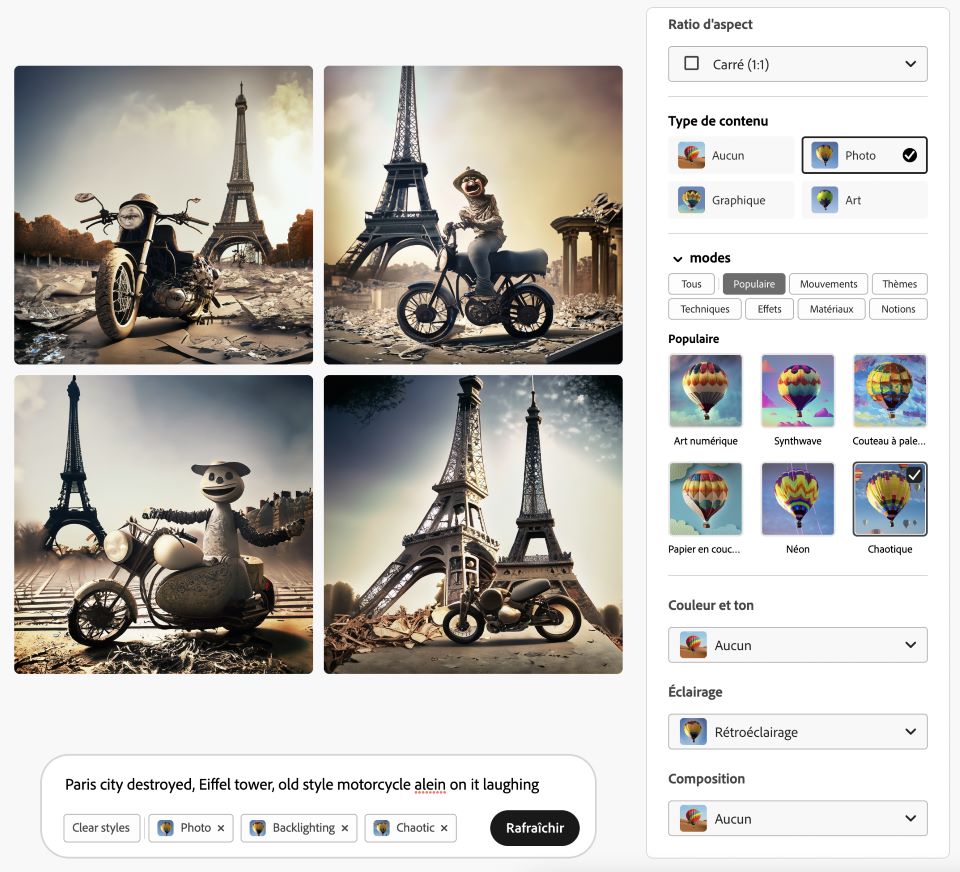

Essayez également Magicstudio, 40 images gratuites/

Site
officiel stablediffusion
Stable diffusion sur son disque dur
Easy Diffusion est une distribution à installer pour utiliser Stable Diffusion, le principal logiciel d'IA de synthèse texte-image open source. Easy Diffusion installe gratuitement tous les composants logiciels requis pour exécuter Stable Diffusion sur sa propre machine (compatible Win/Mac/Linux).
easydiffusion.github.io/
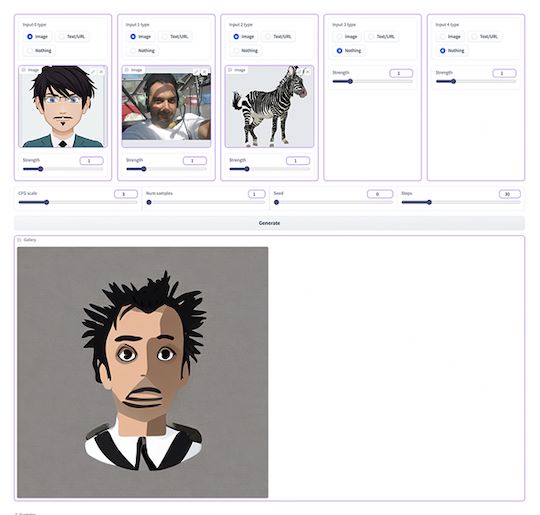

Que peut-on faire avec les générateurs d'images ?
Outre les images d'illustration, les IA peuvent aussi générer :
- Jeux d'icônes, de pictos
- Logos
- Avatars
- Visuels de sites
- …
Dans le chapitre consacré aux faux (personnes, paysages, maison etc.) nous avons vu qu'il est très facile de reproduire des images de personnes qui n'existent pas.
On peut aussi dorénavant leur faire dire ce qu'elles ne disent pas.
Face2Face. Real-time Face Capture and Reenactment of RGB Vidéeos
Cette vidéo montre les possibilités (en 2016) de la reconstitution faciale en temps réel.
Cette technologie (datée, 2016), mise en oeuvre dans la réalisation de deepfakes, peut avoir recours à n'importe quelle voix, la vôtre ou un autre, pour peu de disposer d'un échantillon.
Nous avions évoqué dans le module techno / mytho le travail de la société candyvoice et l'imitation de plusieurs voix, dont celle par exemple d'E. Macron à partir de 10 mn d'échantillon récupérés.
 Dans le domaine de l’apprentissage
automatique, les programmes de DeepMind font
parler. A
quoi est dû ce succès : est-il médiatique, technique ou théorique ?
Dans le domaine de l’apprentissage
automatique, les programmes de DeepMind font
parler. A
quoi est dû ce succès : est-il médiatique, technique ou théorique ?
 Lien vers le
podcast
Lien vers le
podcast
 techno /
mytho
techno /
mythoCitons également descript.com/ qui reproduit n'importe quelle voix à partir d'un échantillon ou les applications de montage automatique, par exemple filmora, GoPro Quik ou Mimo.
Mais là, il s'agit de réaliser des vidéos sans tourner une seule minute de film.
Par exemple sur le site https://app.heygen.com/ vous propose de faire cela de manière très simple.
- Création d'un compte d'essai gratuit
- Création d'un avatar parlant à partir de votre propre photo ou image ou une autre
- Génération d'un avatar IA aléatoire et unique
- Création d'un modèle de vidéo deepfake à partir de votre propre vidéo
- Création d'un modèle de vidéo deepfake à partir de votre photo à l'aide de la fonction d'échange de visage
Sora
Sora peut générer des vidéos d'une durée maximale d'une minute tout en conservant la qualité visuelle et le respect de l'invite de l'utilisateur.
openai.com/sora
Tome
Tome permet de faire une présentation assistée par ordinateur. Après avoir sélectionné un "template", une série de "slides" préremplies sont proposées. Vous pouvez y adjoindre des vidéos, du texte à l'instar de toute autre présentation assistée (genially, Google slide, Power point, Prezi ou Beautiful.ai par exemple).
500 crédits gratuits.





Ou comment créer une image à partir d'un simple dessin au crayon, ci-dessous avec un hamac (désolé pour la piètre qualité du dessin original, mais après tout il s'agit d'un test).

 A partir d'un
simple
dessin au
crayon, il est possible de générer des intérieurs complets, par
exemple une cuisine, un salon, ou alors des paysages et de les faire varier à l'infini.
A partir d'un
simple
dessin au
crayon, il est possible de générer des intérieurs complets, par
exemple une cuisine, un salon, ou alors des paysages et de les faire varier à l'infini.
Pour tous ces sites un compte est obigatoire, à part pour canva, aucune propositon éducation, ce sont donc les tests gratuits qui ont été utlisés.
Maintenant si le hamac n'est pas le sujet, vous pouvez également le générer dans n'importe quel contexte.





